这里我们尝试迁移训练Tensorflow的目标检测模型SSD MobileNet V2 COCO。首先看一下我们的所需要的文件目录:

第一个是labelImg图片标注软件,第二个是Tensorflow模型库,第三个是我们的项目文件。下面让我们以此来配置这些环境。
一、在Ubuntu上安装labelImg
首先下载仓库代码:
git clone https://github.com/tzutalin/labelImg.git进入下载好的文件夹并安装一些依赖软件包:
sudo apt-get install pyqt5-dev-tools
sudo pip3 install -r requirements/requirements-linux-python3.txt
make qt5py3至此安装好了,启动软件可以使用如下命令:
python3 labelImg.py二、下载Tensorflow 模型库
git clone https://github.com/tensorflow/models.git同样如果网络不好的话建议手动下载然后复制到相关目录。
三、安装相关的软件
这里需要注意的是使用pip还是pip3,如果你的电脑中有python2和python3两个版本,请注意选择对应的,我这里使用的是python 3.6。
# CPU版本
pip3 install tensorflow
pip3 install pillow
pip3 install jupyter
pip3 install matplotlib
pip3 install lxml鉴于之前安装OpenVINO时已经安装了Tensorflow,所以这里可能显示已经安装了。
如果你想安装Tensorflow GPU版本,可以使用以下命令并配置CUDA:
# GPU版本
pip3 install tensorflow-gpu到这个网址下载最新的Protobuf库,比如说protoc-3.11.1-linux-x86_64.zip,然后放在models/research目录下解压:
unzip protoc-3.11.1-linux-x86_64.zip然后运行编译过程,注意在目录models/research目录下:
./bin/protoc object_detection/protos/*.proto --python_out=.在本地运行时,models/research和models/research/slim目录需要添加到PYTHONPATH,可以通过在目录models/research下运行命令:
export PYTHONPATH=$PYTHONPATH:`pwd`:`pwd`/slim需要注意的是每次打开新终端时,都要输入这个命令,想方便的话可以将上面两个目录的绝对路径添加到~/.bashrc文件的末尾。
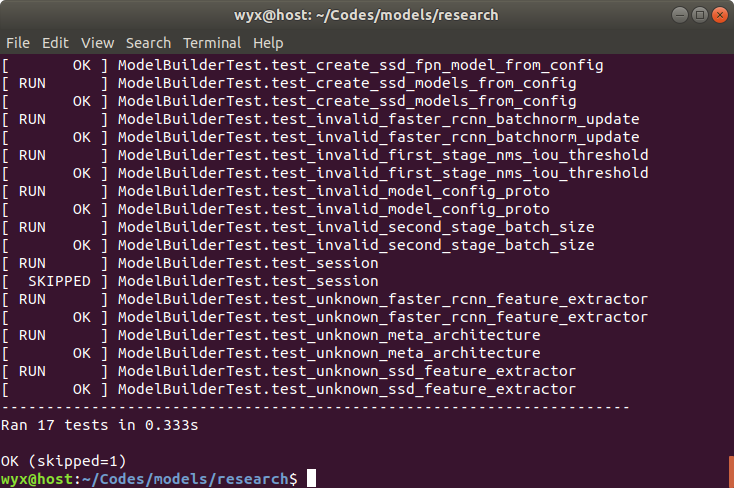
然后可以测试一下安装是否成功:
python3 object_detection/builders/model_builder_test.py出现以下输出说明安装成功:
因为models目录里有太多其他的文件了,我们只需要用到目标检测模块,所以搭建好环境之后我们自己新建一个项目文件夹,这样的话更加清楚文件的结构。
首先新建Object-Detection,然后将models/research中的object_detection文件夹和slim文件夹复制一份到Object-Detection文件夹中。
四、数据集制作
在Object_Detection/object_detection/data目录下新建一个文件夹VOC2007,文件名可以自己设定,接着在这个文件夹中新建4个文件夹,分别为JPEGImages,Annotations,ImageSets,Tools。搜集好的图片放在JPEGImages目录下,标注后的数据保存在Annotations目录下。
首先我们在网上搜集了三个类别的图片,分别是人、汽车和树,每个类别各50张。由于一开始的图片大小不统一,为了方便操作,我们用美图秀秀批处理助手把这些图片都转成了统一大小的图片了,然后我们把这些原图片放在JPEGImages目录里。当然也可以通过脚本转换。
在使用标注软件之前,我们需要把图片的文件名格式统一化,这样标注文件的名字也会同样具有统一的格式,这样的话就方便后面写程序处理,为此我们在Tools文件夹中已经写一个batch_rename.py脚本。
#!/usr/bin/python3
# -*- coding:utf8 -*-
import os
import sys
class BatchRename():
def __init__(self):
#给定目标目录
self.path = '../JPEGImages'
def rename(self):
filelist = os.listdir(self.path)
total_num = len(filelist)
print ("total_num : %d" % total_num)
i = 1
for item in filelist:
if item.endswith('.jpg'):
n = 4 - len(str(i))
src = os.path.join(os.path.abspath(self.path), item)
dst = os.path.join(os.path.abspath(self.path), str(0)*n + str(i) + '.jpg')
try:
os.rename(src, dst)
print ('converting %s to %s ...' % (src, dst))
i = i + 1
except:
continue
if __name__ == '__main__':
demo = BatchRename()
demo.rename()运行该脚本,可以统一图片的文件名。接着我们启动labelImg软件,进入到labelImg目录,终端输入:
python3 labelImg.py软件启动后,我们可以设定打开的图片文件目录为之前的JPEGImages,输出保存的目录为Annotations,然后按w按键,会出现十字,然后按住鼠标左键,拖动,直到将全部目标包括在内,注意,选择区域尽量小。然后放开鼠标,在文本框中输入类别名称,比如:tree。
然后点击save保存。接着可以点击Next Image下一张,以此类推来进行图片标注。
标注好以后,为了训练,我们需要将数据集分成训练集、验证集和测试集。为此,我们先在ImageSets目录下新建一个Main文件夹,然后用我们写的脚本来自动生成这些数据集的文件名列表,运行data_split.py脚本,将会在Main目录生成test.txt,train.txt,val.txt,trainval.txt四个文件。其中,train.txt是用来训练的数据集文件名列表,而val.txt是用来验证的数据集文件名列表,其实在我们训练自定义模型的时候,只需要这两个文件。
#!/usr/bin/python3
# -*- coding:utf-8 -*-
import os
import random
trainval_percent = 0.9 # trainval占总数的比例
train_percent = 0.8 # train占trainval的比例
xmlfilepath = '../Annotations'
txtsavepath = '../ImageSets/Main'
total_xml = os.listdir(xmlfilepath)
num = len(total_xml)
lis = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(lis, tv)
train = random.sample(trainval, tr)
ftrainval = open(txtsavepath + '/trainval.txt', 'w')
ftest = open(txtsavepath + '/test.txt', 'w')
ftrain = open(txtsavepath + '/train.txt', 'w')
fval = open(txtsavepath + '/val.txt', 'w')
for i in lis:
name = total_xml[i][:-4] + '\n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftrain.write(name)
else:
fval.write(name)
else:
ftest.write(name)
ftrainval.close()
ftest.close()
ftrain.close()
fval.close()在object_detection/data路径下新建barrier_detection_label_map.pbtxt文件,编辑以下内容:
item {
name: "person"
id: 1
display_name: "person"
}
item {
name: "car"
id: 2
display_name: "car"
}
item {
name: "tree"
id: 3
display_name: "tree"
}表明我们需要检测三类物体,分别是人、车和树,对应的ID分别为1、2、3。
五、模型转换
由于此数据集是我们自己制作的,保存格式模仿了PascalVoc(与ImageNet采用的格式相同),而tensorflow提供了将PascalVoc格式的数据集转换成tfrecored格式的脚本,路径为Object_Detection/object_detection/dataset_tools/create_pascal_tf_record.py,我们直接修改一下使用就好了,这也是为什么之前我们要创建对应的文件夹的原因。修改的关键主要使各个文件的路径,你可以输出一些看一下是否正确,这里给出修改后的文件和源文件使用diff命令的结果,可以仔细对照:
85,88c85
< #img_path = os.path.join(data['folder'], image_subdirectory, data['filename'])
< print("data['folder']", data['folder'])
< print("data['filename']", data['filename'])
< img_path = os.path.join('VOC2007', data['folder'], data['filename'])
---
> img_path = os.path.join(data['folder'], image_subdirectory, data['filename'])
90,92d86
< print("dataset_directory:", dataset_directory)
< print("img_path:", img_path)
< print("full_path:", full_path)
171c165
< FLAGS.set + '.txt')
---
> 'aeroplane_' + FLAGS.set + '.txt')
接下来你可以在命令行运行这些转换的脚本,但是因为对应的命令较长,为了方便我们把运行的命令也写成一个脚本create_tfrecord.sh,内容如下:
python3 object_detection/dataset_tools/create_pascal_tf_record.py \
--label_map_path=object_detection/data/barrier_detection_label_map.pbtxt \
--data_dir=object_detection/data --year=VOC2007 --set=train \
--output_path=object_detection/data/barrier_train.record
python3 object_detection/dataset_tools/create_pascal_tf_record.py \
--label_map_path=object_detection/data/barrier_detection_label_map.pbtxt \
--data_dir=object_detection/data --year=VOC2007 --set=val \
--output_path=object_detection/data/barrier_val.record然后将其放入Object_Detection目录,注意这个脚本中的文件路径,特别是反斜杠之后没有空格,我就因为这个栽了大坑,如果你之前设置的不一样的话需要对应修改。我们为脚本添加执行权限然后运行:
chmod +x create_tfrecord.sh
./create_tfrecord.sh这样就能在目录Object_Detection/object_detection/data目录生成两个数据文件:barrier_train.record和barrier_val.record。
六、模型训练
在Object_Detection/object_detection目录下新建ssd_mobilenet目录,将下载好解压的文件放入这个目录。将这个目录里的管道文件pipeline.config复制一份并更名为pipeline_2018_03_29.config,对新的文件做以下修改:
修改类别数:
num_classes: 5修改训练模型位置,建议使用绝对路径:
fine_tune_checkpoint: "/<yourpath>/Object_Detection/object_detection/ssd_mobilenet/ssd_mobilenet_v2_coco_2018_03_29/model.ckpt"修改训练次数:
num_steps: 1000修改训练数据位置:
train_input_reader {
# 标签映射配置文件路径
label_map_path: "/<yourpath>/Object_Detection/object_detection/data/barrier_detection_label_map.pbtxt"
tf_record_input_reader {
# 训练集路径
input_path: "/<yourpath>/Object_Detection/object_detection/data/barrier_train.record"
}
}修改验证数据位置:
eval_input_reader {
label_map_path: "/<yourpath>/Object_Detection/object_detection/data/barrier_detection_label_map.pbtxt"
shuffle: false
num_readers: 1
tf_record_input_reader {
input_path: "/<yourpath>/Object_Detection/object_detection/data/barrier_val.record"
}
}Tensorflow官方提供了训练的脚本,路径为
Object_Detection/object_detection/legacy/train.py,所以我们可以直接使用它来开始我们的迁移学习训练,在目录Object_Detection目录下新建一个训练的脚本文件train.sh,并写入以下内容:
# 如果不存在这个路径,就递归地创建它
if [ ! -d "object_detection/ssd_mobilenet/train_logs" ]; then
mkdir -p object_detection/ssd_mobilenet/train_logs
fi
# 设置管道配置文件的路径
PIPELINE_CONFIG_PATH=object_detection/ssd_mobilenet/pipeline_ssd_mobilenet_v2_coco_2018_03_29.config
# 设置模型训练过程中产生的记录文件的存放位置
TRAIN_LOGS=object_detection/ssd_mobilenet/train_logs
# 运行train.py文件
python3 object_detection/legacy/train.py \
--logtostderr \
--train_dir=$TRAIN_LOGS \
--pipeline_config_path=$PIPELINE_CONFIG_PATH文件夹train_logs中存放模型训练过程中产生的记录文件,可以用来导出我们需要的模型。然后运行脚本就可以开始训练:
./train.sh可以在训练的时候可视化训练过程,新开一个终端,在Object_Detection目录下运行:
tensorboard --logdir=object_detection/ssd_mobilenet/train_logs在浏览器打开http://localhost:6006,即可看到loss等信息的实时变化。
七:导出模型
进入train_logs目录,可以看到一些文件如下:
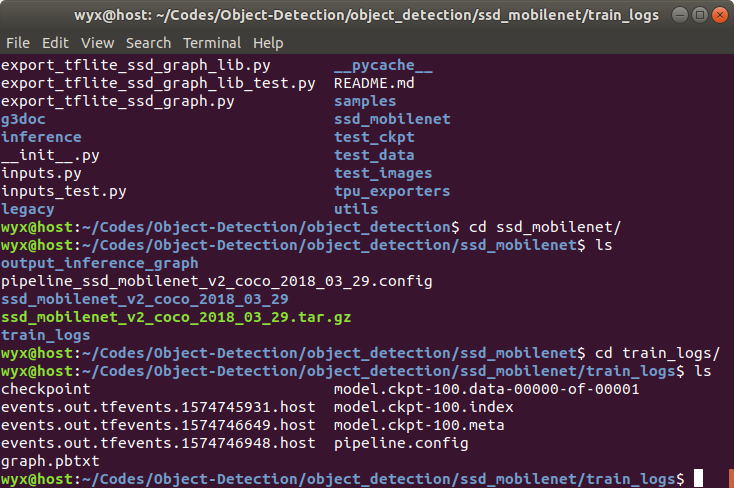
仍然可以用Tensorflow官方的脚本导出训练好的模型,该脚本路径为
object_detection/export_inference_graph.py
在Object_Detection目录下新建一个脚本export_model.sh,写入以下内容:
# 如果不存在这个路径,就递归地创建它
if [ ! -d "object_detection/ssd_mobilenet/output_inference_graph" ]; then
mkdir -p object_detection/ssd_mobilenet/output_inference_graph
fi
# 运行export_inference_graph.py文件
python3 object_detection/export_inference_graph.py \
--input_type image_tensor \
--pipeline_config_path object_detection/ssd_mobilenet/pipeline_ssd_mobilenet_v2_coco_2018_03_29.config \
--trained_checkpoint_prefix object_detection/ssd_mobilenet/train_logs/model.ckpt-100 \
--output_directory object_detection/ssd_mobilenet/output_inference_graph然后运行:
./export_model.sh导出后的文件内容和我们下载的预训练模型类似,至此,我们自己的模型已经训练完成。在此基础上你可以像之前那样将这个模型也转换成OpenVINO的IR格式文件。
留言